
Travel x AI: "Horizontal" LLMs Structurally Designed to Go Vertical
It's not an API and ecosystem strategy. They have incentives to go vertical.

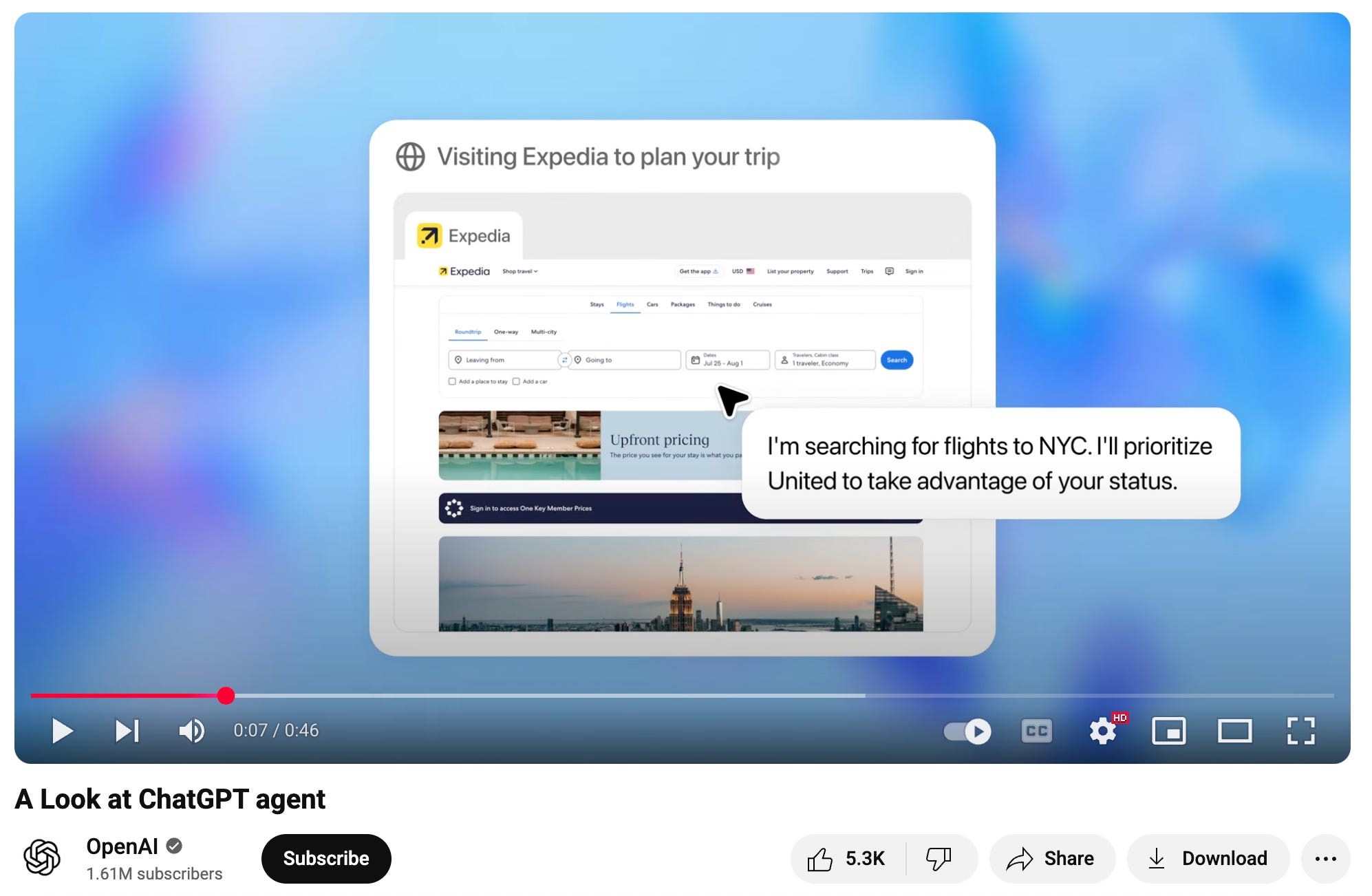
Last week, OpenAI debuted their agent, demoing functions like booking travel, creating spreadsheets, and even designing slides. It’s a combination of their Operator (great at online tasks like booking reservations, sending emails, etc.) and Deep Research (great at in-depth internet research and output reports).
Gemini is developing Project Astra with an angle for live, multi-modal angle interpreting videos and images. Perplexity is building their own agents. All of them are moving to compete not only with search, but also directly with apps.
The dominant view was that foundational model players will compete in search, like Google, but focus on being a horizontal player by enabling AI-players with their models, just as Apple did with the App store. I think it’s a little messier than that.
LLMs are moving beyond APIs to own application-layer-verticals.
My early thoughts are based on the following:
LLMs are shaping new forms of search rapidly: LLM search already takes up ~1-5% of the market. ChatGPT, as proxy for independents, has reached 6:1 daily query ratio against Google Search. Google, as proxy for incumbents, integrated AI Overview and AI Mode showing willingness to cannibalize to win this new search. At the same time, the typically lagging consumer adoptions are matching the pace growth.
LLM search has little incentives to surface 3rd party information: Google relied on organizing information of others for value. LLMs have no incentive to surface or partner unless they provide direct functional utility to users. Human web traffic for LLM search users have already been compressed by 80%. All major partnerships with LLMs have been centered on functional utility, not information.
LLMs have structural incentives to go vertical: LLM apps have significantly higher product leverage than API. Subscriptions have held their price as compute costs became 10x cheaper every year. APIs are approaching cost plus. With checkout directly on the app, LLMs will “double-dip” on all transactions that occur. Players are moving: OpenAI (CEO of applications), Perplexity (formalized verticals), Anthropic (Claude of Financial Services).
Covering the entirety of agentic AI would be too broad. I’ve designed this piece to be a brief view of how LLMs are rapidly changing the future of search, and why the new form is structurally incentivized to own the full stack.
Search is Changing Faster Than What Most Can Prepare For
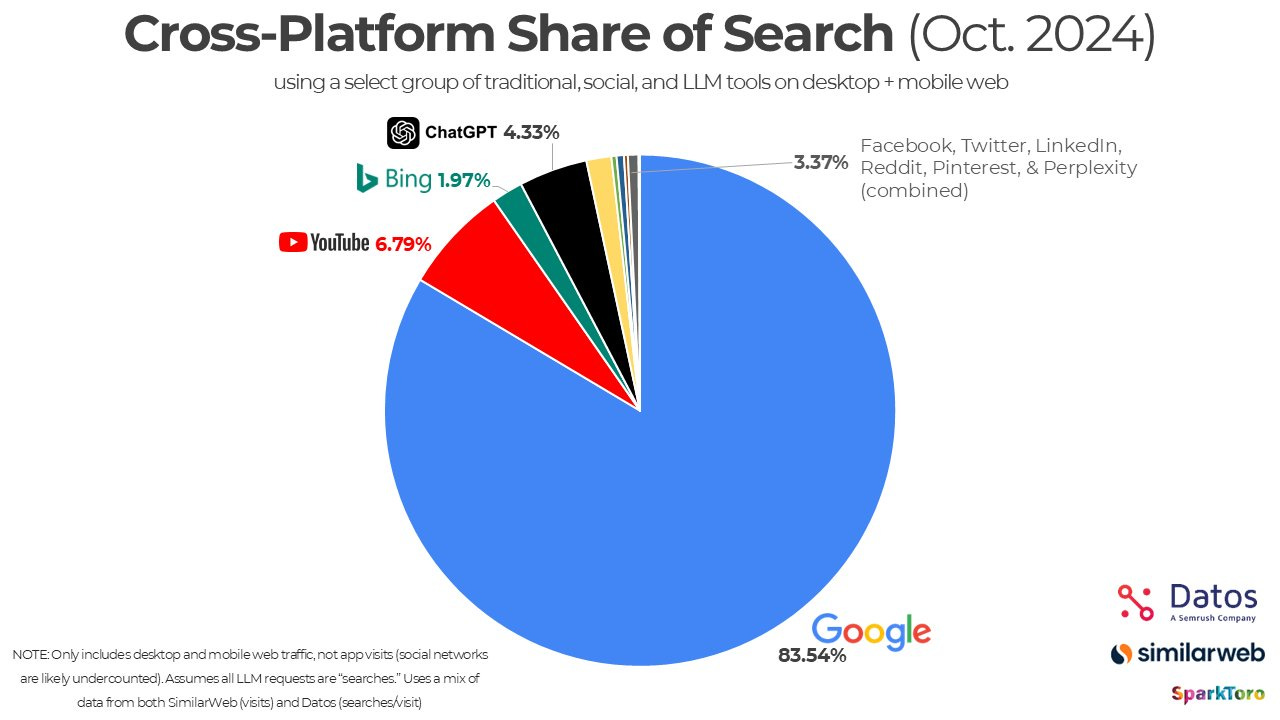
LLM search today are making up anywhere from 1-5% of the search market, depending on the methodology and definition of “search” (i.e. not all prompts are technically search). A rough estimate from a third-party examining search web traffic is below:
To be precise, “search” and “agents” used to be distinct in consumer LLM interfaces like ChatGPT and Claude. Search typically relied on frozen training data with a cutoff date, while agents used live tools like web browsers to fetch real-time information. But the lines are blurring, where models now integrate browsing into default experiences. For simplicity, I’ll refer to this merged capability as LLM search.
When I do a quick sanity check of the market, the daily search volume of Google is about 14 billion and ChatGPT reports 2.5 billion as of July 21, 2025. That’s about a 6:1 ratio. Even if we assume nearly half of prompts are completely unrelated to search, a 3:1 ratio against Google is pretty damn good.
But there are two even more important observations to track:
Observation 1: The rapid rate of growth that hasn’t even matured
OpenAI is growing faster than any player they’ve seen, according to Coatue, a respected public-private fund with $70B AUM, in Coatue View on the State of the Markets.
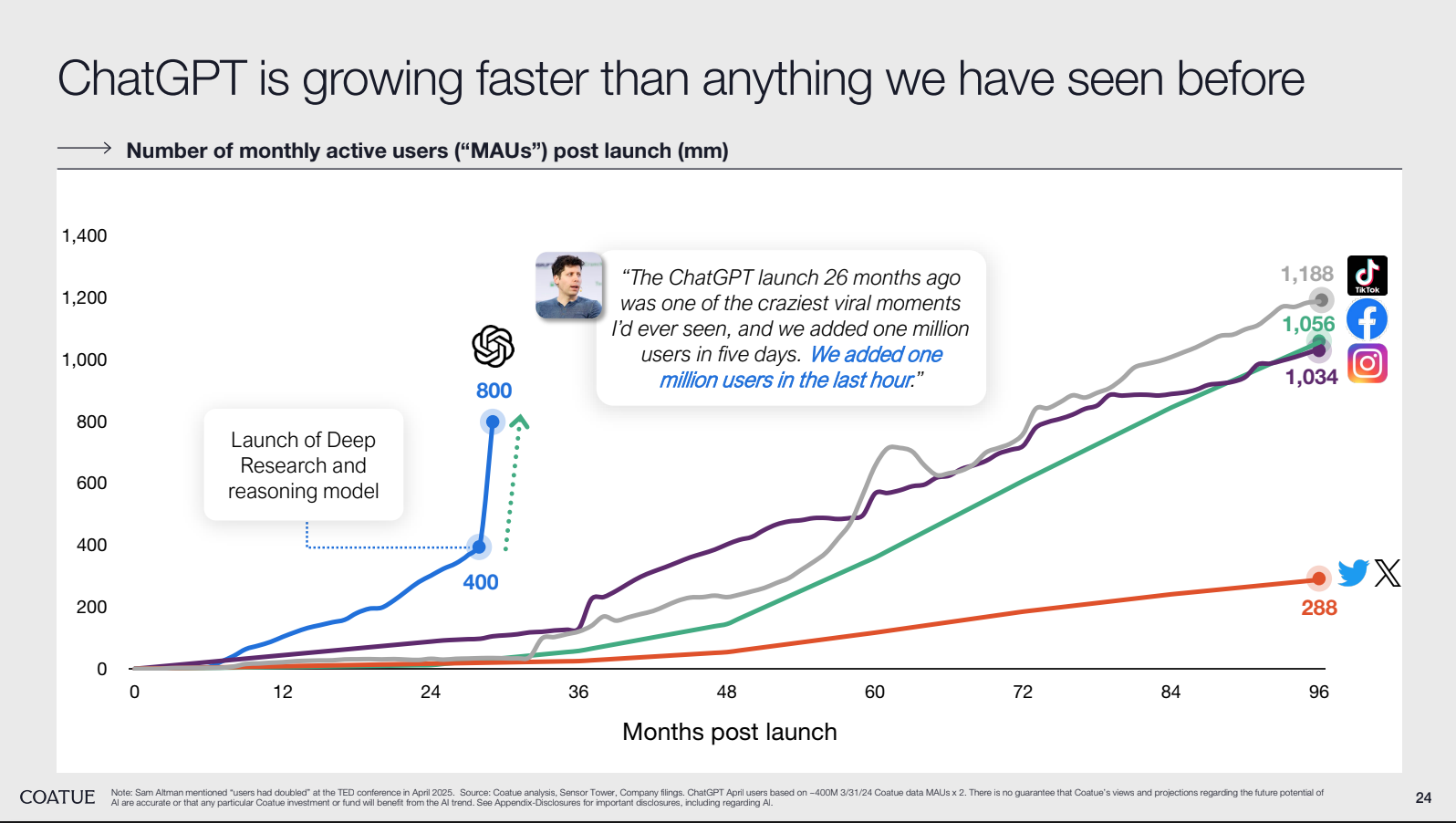
It’s every startup’s dream to own “just 1%” of a large market, but at their rate, it looks like that 1% can quickly become 10, 20, 30%. Because the data is early and private, let’s take a reasonable assumption that the total search volume is roughly a function of:
Total # of Users
Average search volume per user
Simple, but foundational models haven’t matured in either one of these metrics.
Total # of Users: In terms of users, ChatGPT, for example, has just 1B users (excluding SearchGPT in beta) compared to several billion users of Google. Even Google deployed their own AI Overview and “AI mode” cannibalizing on their search.
We then still need to take into account other tech giants like Microsoft’s Co-pilot and X’s Grok as well as independent foundational models like Anthropic’s Claude and High-flyer’s Deepseek.
Even if we account for double-counting in terms of correlations (i.e. people will use multiple search products), the volume is growing rapidly. The other lever is the average search volume per user
Average search volume per user: There are speculations that average search volume may increase as search itself becomes more valuable (agents can do more), but there hasn’t been public, concrete evidence yet. The nature of search does seem to suggest different ways to engage. A16z’s analysis suggests:
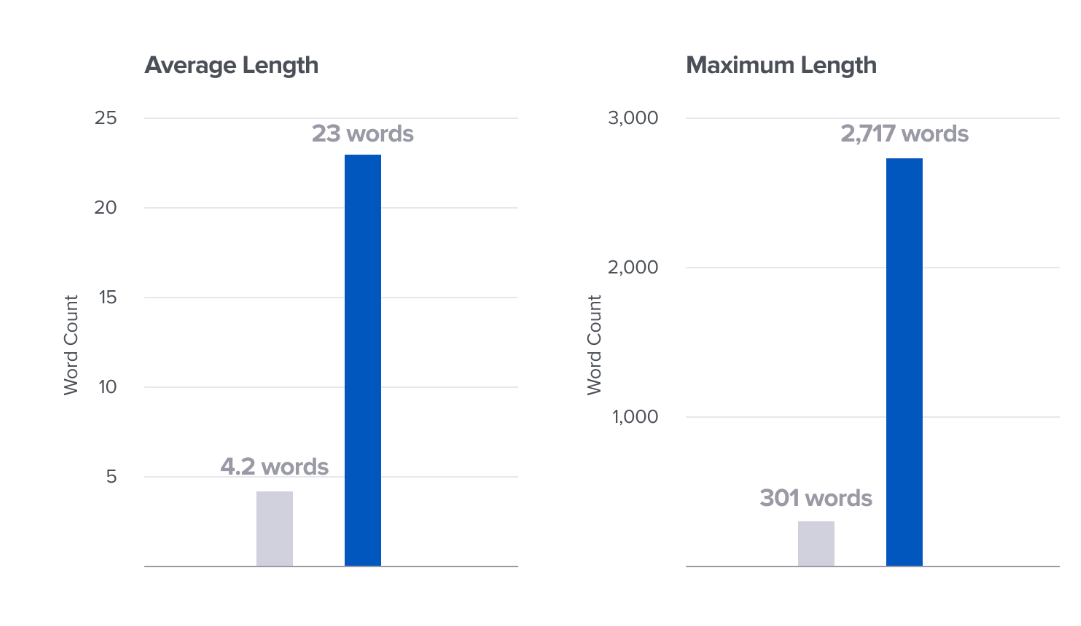
Queries are longer (23 words, on average, vs. 4), sessions are deeper (averaging 6 minutes), and responses vary by context and source.
Unlike traditional search, LLMs remember, reason, and respond with personalized, multi-source synthesis. This fundamentally changes how content is discovered and how it needs to be optimized.
So consumer behavior also seems to be adapting faster than ever to the new form of search. The core user flow of “search” or “chat” is kept in place without additional compromise on data and privacy, but the value increases enormously.
That new search model radically changes incentive structures for all parties involved, which brings me to the second observation.
Observation 2: Structurally different incentives and economics
The LLMs taking up search market is different than competitors like Bing or regional players like Naver fighting for market share. It’s a fundamentally shifting incentives and dynamics in a new form of search.
The previous generation of technology was about ecosystems — even if monopolistic nature and pricing raised concerns — because that’s how they generated value.
Google relied on information of others. Google didn’t produce first-person information, but indexed and organized information of others. Even if they charge with Adwords, SEOs allowed for organic search, and the structure incentivized collaboration.
Apple’s app store relied on software of others, including billion-dollar consumer companies like Uber, Instagram, and RobinHood. Despite taking a whopping 30% (and now much less due to US ruling), there was strong incentives to create a bigger pie for everyone.
LLM is a different beast.
The structural changes of the new platform is why I’m not quite convinced that LLMs is just about empoweringAI-applications with their foundational models.
While it’s true that many “LLM-wrappers” benefiting through shared API, LLM players seem to be moving to not only own search, but the full stack — not because these companies are less virtuous than previous generation of tech companies, but because of how incentive structures are set.
Little Incentives For Ecosystems
Unlike Google’s search, LLMs can provide all information value to users without reliance on third-party information. That means there is no incentive for LLMs to cite or link to external sources, unless there is tangible value in doing so. In fact, many citations to external sources seems to be for hedging against hallucination.
Once the “hallucination problem” becomes relatively solved, the reliance on external sources for credibility will diminish.
That’s not just an intuition. Though dated by a few months, Bain & Company published that about “80% of search users rely on AI summaries at least 40% of the time.” And Pews Research Center, also directionally corroborated these findings.
A16z’s Zach Cohen and Seema Amble, echoed this point “there’s less of an incentive by model providers to surface third-party content, unless it’s additive to the user experience or reinforces product value.”

Then came Google’s AI Overview and AI Mode integration directly into search. Fortune described this as “cutting off the oxygen to the web,” reducing web traffic of people by as much as 80%. There are at least two second-order thought to consider as we see a split of human vs. agent clicks:
1.Traffic will die: If 80% (4/5) of human clicks are disappearing, then one of three things must happen for human clicks to maintain current revenues: Total conversion must increase by at least 5x (combination of average search volume and average conversion rate).
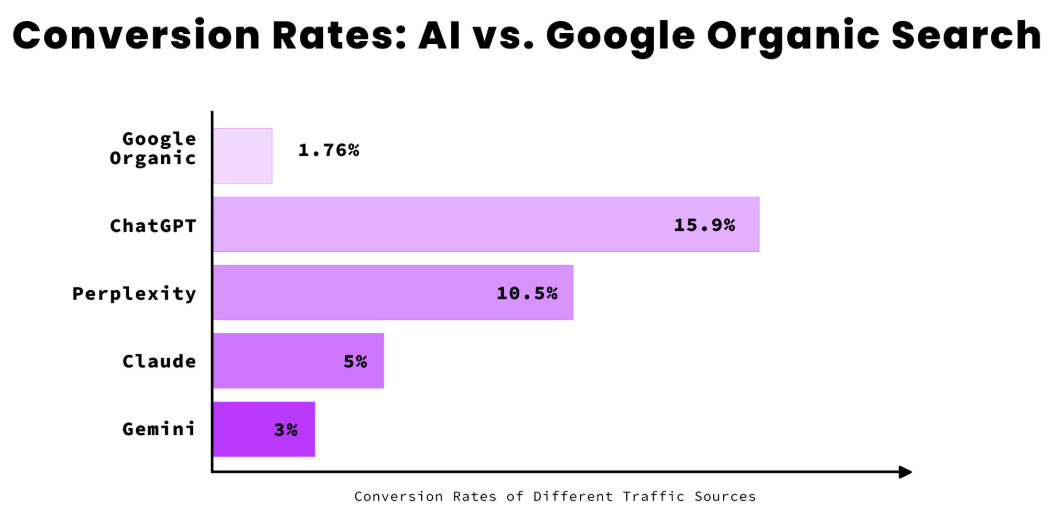
Early data today suggests that it’s achievable, but it’s uncertain if it’ll be sustainable. Perhaps hallucination will never be fixed and remain a necessary evil in the way LLMs are structured. But if they do become minimal and consumers adapt to trusting LLMs, there won’t be many structural reasons to surface third party data.
Some external referencing and citation will persist due to regulation (i.e EU’s transparency regulation), edge cases for long papers/ content inefficient to generate, and anti-trust optics (many are already outraged) will keep some of it around.
But the incentives structures are clear.
2.Less effective tools: The traditional web traffic can surge 100x or more. If user queries are is fanned out, the machine clicks, will increase. Already we see a surge in bot activity, with over 50% of web traffic attributed to bots according to analysis by Stan Ventures.
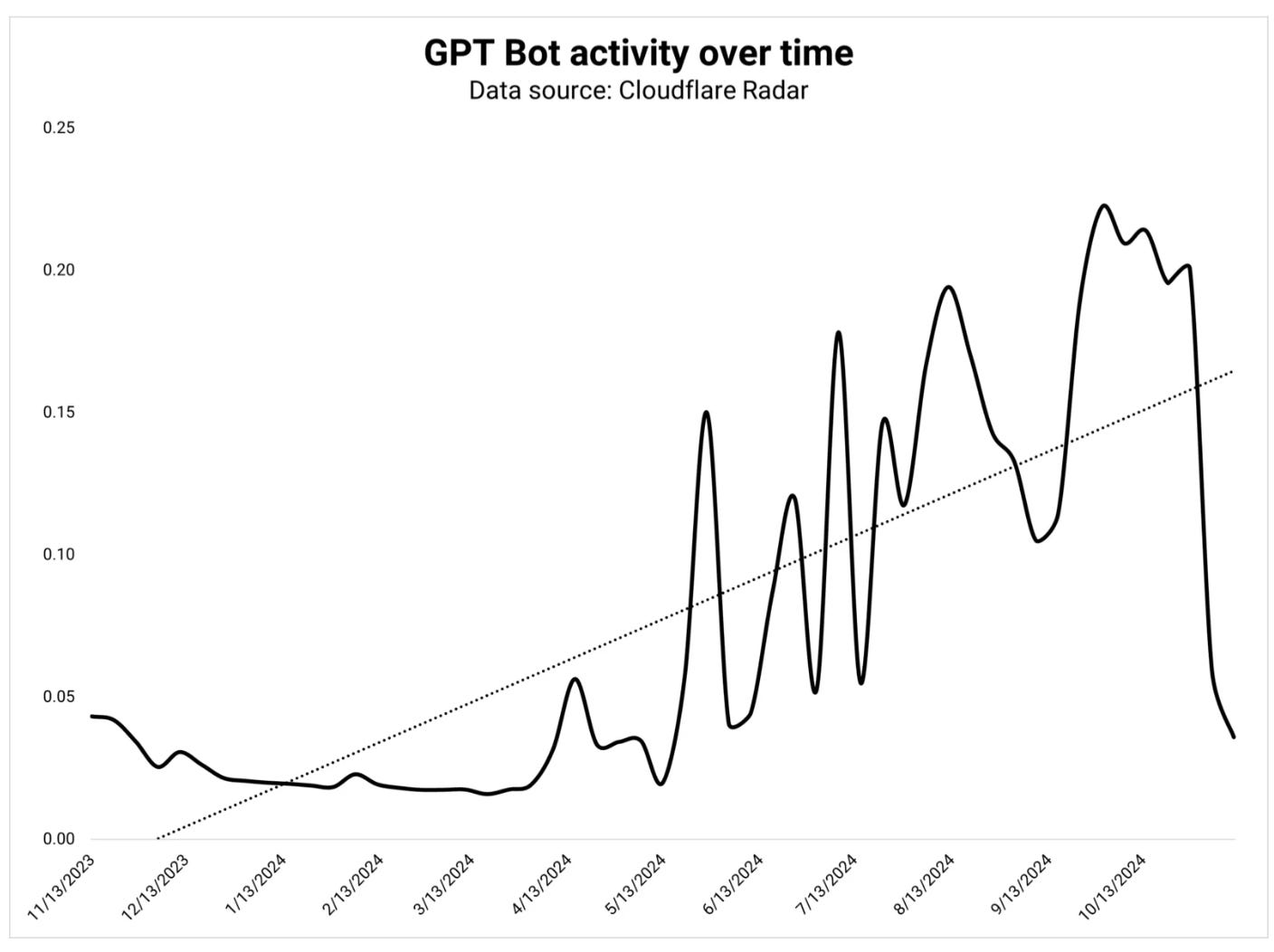
Data from Cloudflare, a cloud service that makes websites load faster and stay safe by filtering traffic through its global network, suggests that these bot activities aren’t just from traditional web-crawlers, but driven by surge of LLM bots both for information gathering and agentic search, with at least two implications:
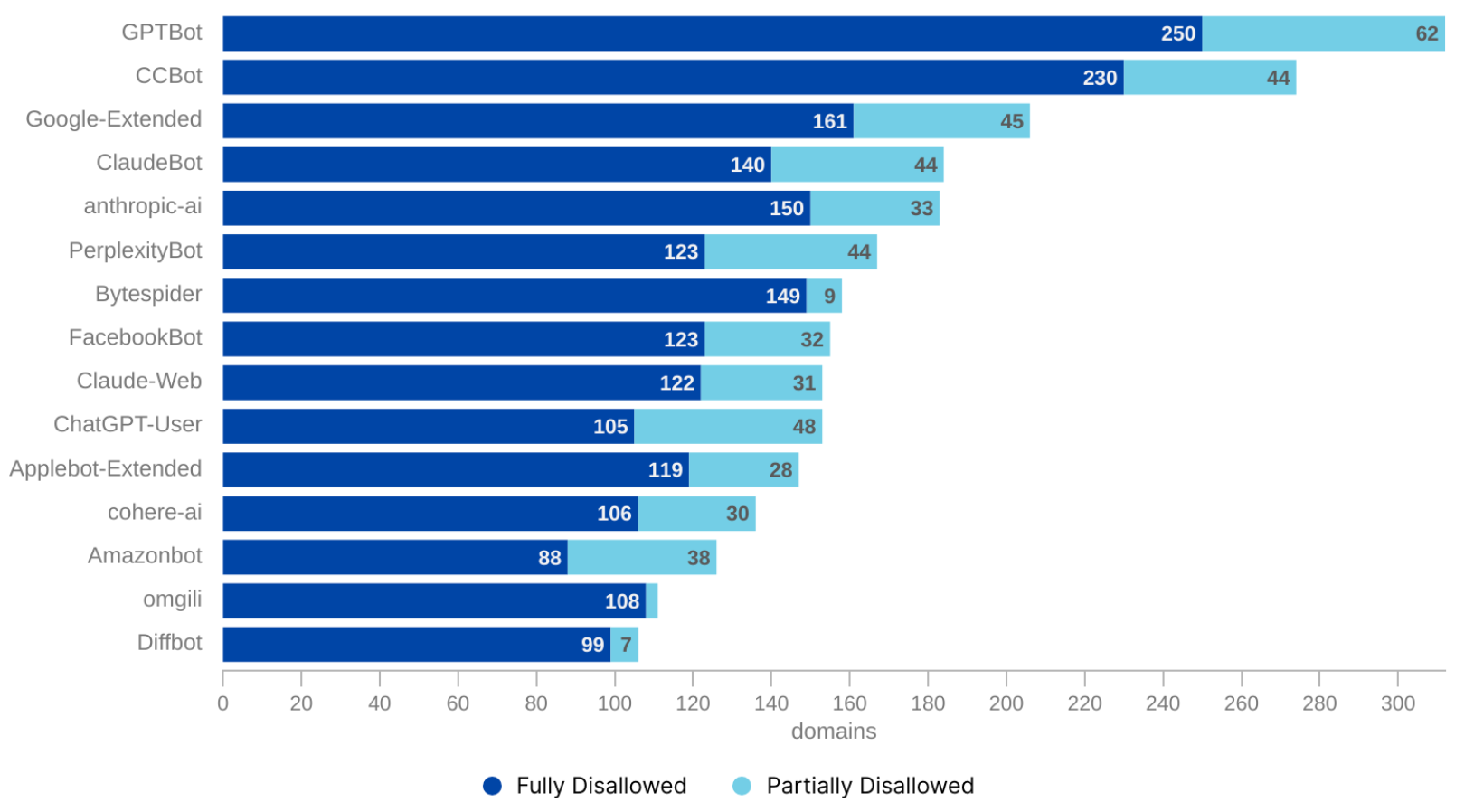
Exponential noise and costs for Ads: Web traffic increasing by 100x provides makes signal infinitely harder to capture for search-based companies, potentially leaving customers stranded on websites. More importantly, while Google Adwords and other ad companies have defenses, many of these agents can start imitating “human activity,” which would create a massive cost per click problem.
No exposure from SEOs: Traditional SEO was somewhat linked to exposure and branding. During the search period, user may learn about the brand and eventually convert. If agents are doing the initial screening, users don’t see the brand at all. Exposure and accidental finds to conversion disappears.
Put the two together (1) LLM compressing human traffic down to 20% (of course, not entirety of search, but LLM search) and exponentially increasing noise from machine traffic (2) Traditional tools like ads and SEOs becoming less effective, search-based companies almost forced to give information for free. It’s probably why some are already calling AI Mode “theft.”
So LLMs have free, easy access to information, so the value is going to come from something else: context and functions. That’s probably why most formalized partnerships directly integrated with LLMs have been less about information and much more about functional utility, including:
Access to data: Creating a “vault” of information for greater context and execution.
OpenAI prioritized connections to Dropbox, Google Drive, One Drive, SharePoint, and Github, all information repositories for better user data. They’ve also partnered with companies for data sets.
Anthropic has Model Context Protocol (MCP) connecting to Notion, Gmail, Asana, and Canva.
Gemini has direct extensions of Google products from Gmails, Drive, Docs, Calendar, and more for greater user context.
Functional: Add value by actually completing the task for users
OpenAI, for example, partnered with Shopify, where users can shop directly on the ChatGPT interface, without going off platform. Zapier integration with ChatGPT is also an example of function-based partnerships that increases utility and retention of the interface, without surfacing external players.
Anthropic similarly chose “10 popular services” including Jira, Intercom, Asana, Square, PayPal, Linear, and Plaid.
Gemini enabled third‑party extensions (Kayak, OpenTable, Instacart, Zillow, Adobe Firefly) maintain task execution in‑app.
Free information is understandable, but why are these so called “horizontal” investing so much in functions? Because they’re structurally designed to do so. They are headed further down the value chain, “verticalizing” in application layers.
Structural Incentives to Own Verticals
As a preface, foundational model players have birthed extremely useful API-enabled LLM wrappers and partnership.
However, it’s also true that LLM players are explicitly building verticals. Perplexity formalized finance, travel, shopping, and academic verticals, and will continue to build these out.
OpenAI now has a CEO of application joining as of August 18, 2025. Fidji Simo, former CEO of Instacart, who’ll take the role, has already hinted at entering all sorts of verticals from knowledge, health, arts, and finance.
Meanwhile, Anthropic launched Claude for Financial Services July 15, 2025.
That seems counterintuitive.
Foundational models invested billions to build the models, so why not provide the shovel and let others do the hard work of mining the gold? Apple didn’t obsess over developing a million apps after building the Appstore and Google didn’t focus on making a billion websites after building their search engine.
So why are LLMs focus on owning the entire stack up to the application layer? If we follow the money, we’ll see that applications not only provide more revenue and profit, but also have greater product leverage, at least in the short-term.
Consumer-apps have greater product leverage for LLMs
OpenAI recently hit $10B in ARR up from $5.5B last year. Though the split is older, over the CFO noted 75% of that revenue came from paying consumers (i.e. chatbot, and not the API) product.
Some older estimates show that only about 15% of revenue came from APIs.
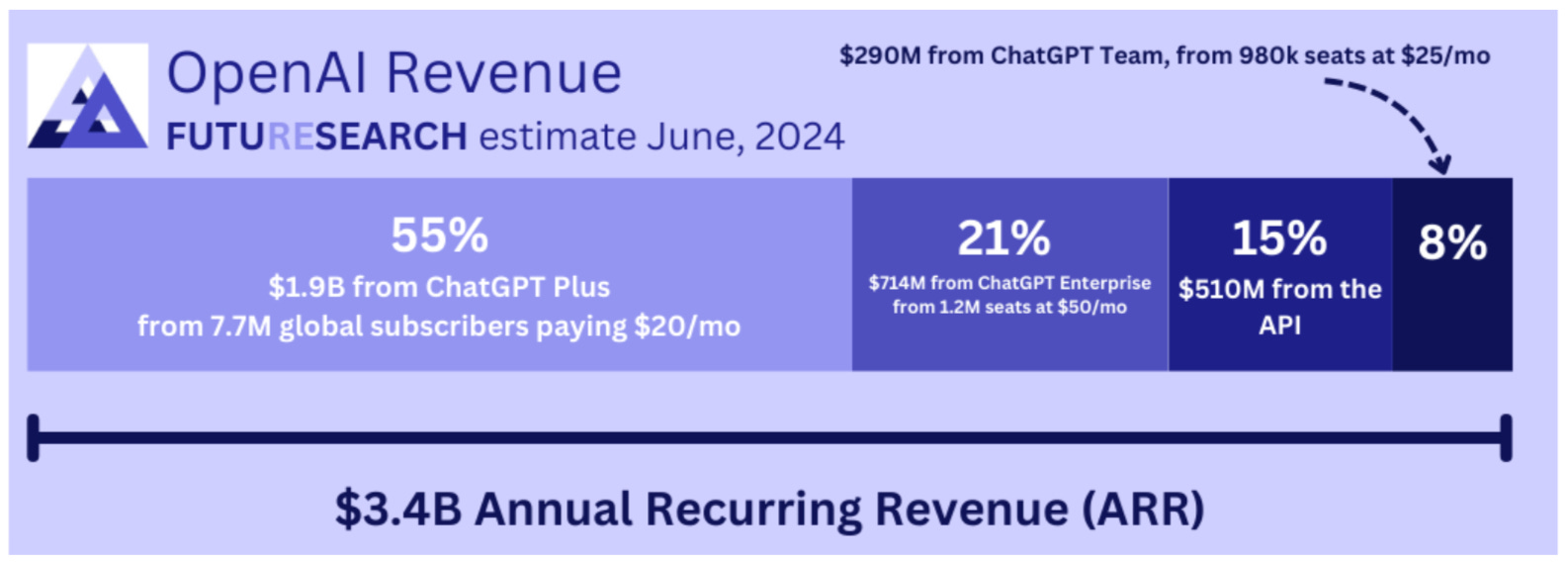
Even on a profitability perspective, subscriptions fees have maintained their fixed price at around $20/ month with premium options, while the cost of compute have been decreasing rapidly. In fact, Sam Altman, CEO of OpenAI noted “the cost to use a given level of AI falls about 10x every 12 months.”
The same can’t be said for APIs, where cost per million tokens have been falling, and will probably head towards cost-plus for API users over the short-term. Estimates from a research company (I’d take it purely directionally), suggest depression in unit economics.
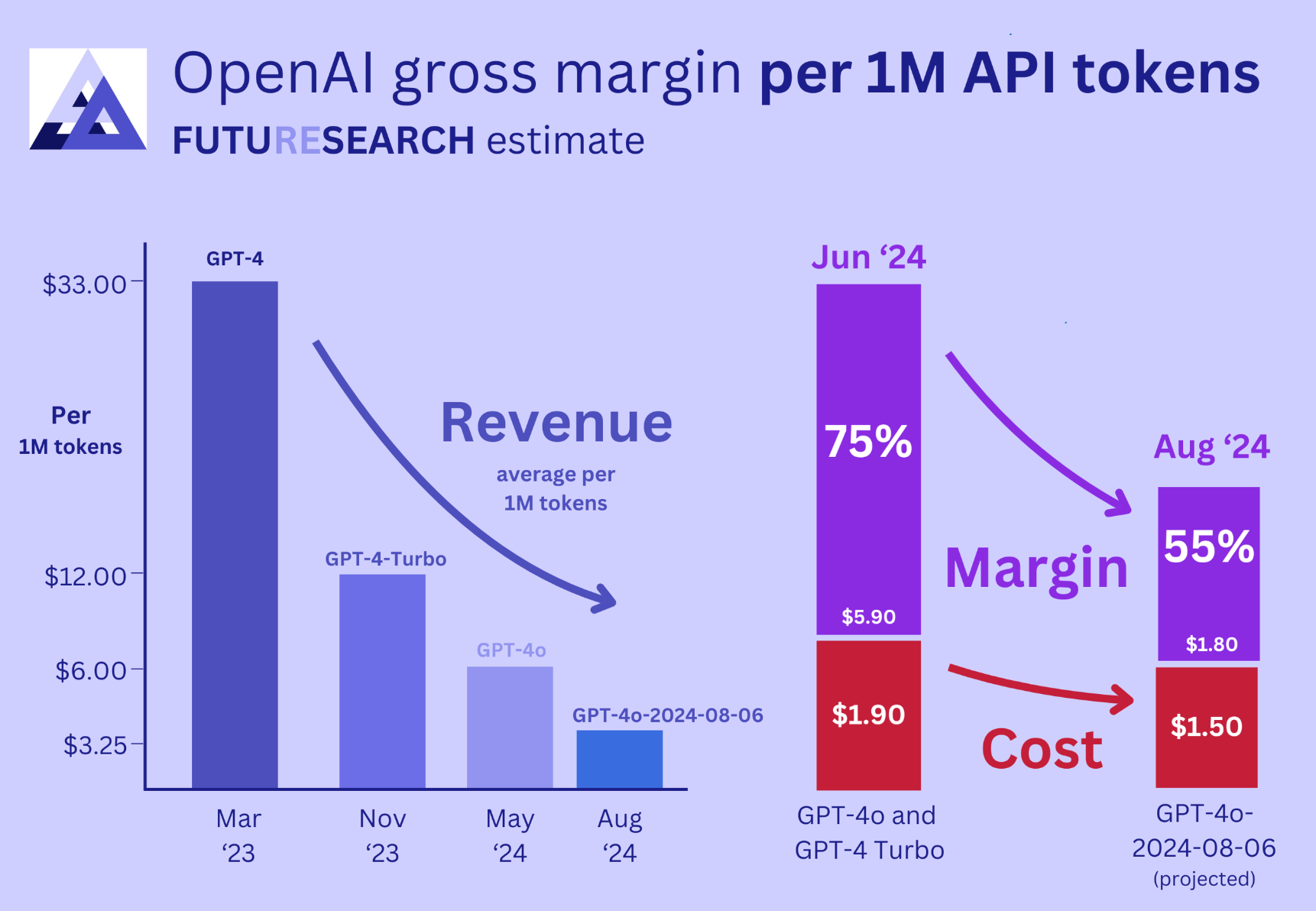
While the API business has a shot at becoming large and profitable as the cloud predecessors (AWS, Azure, etc.) did through related costs (storage, networking vs. cloud storage), it’ll take time.
In the short-term, consumer interfaces has more product leverage
Double, triple, quadruple dipping
Another concrete product leverage is integration of payment checkout systems, which essentially allows double dipping:
Subscription revenue from consumers
Take rates from companies
That’s not all. Perplexity openly claimed they will be reconstructing an ads like Google, noting they’ll “hyper-personalized ads.” That’s now a third revenue stream for these consumer-interfaces. Tech crunch notes that both OpenAI and Perplexity "said they would “buy the Chrome browser business if Google was forced to sell” due to anti-trust regulation.
These additional revenue streams are necessary when comparing LLM consumer interfaces to traditional SaaS, because every query creates a variable cost. Even with smart rate-limits and pricing, they will almost always have worse unit economics, which is why new revenue streams are useful to offset and even exceed the higher variables costs of LLMs compared to traditional SaaS.
While core investments still like with scaling data centers and improving foundational models will probably be the focus, there will be considerable effort from every LLM player to move in this direction (even in the case of Anthropic where most revenue was from APIs in early analysis).
That’s not to say LLMs won’t continue building API side so they gain more value and influence as companies use them, but that unlike Google and Apple, they are structurally designed to continue building verticals themselves.
Future of how the core consumer interface will interact has many uncertainties. Perhaps their core agents will interact with industry specific “middle-layer” agents like Plaid did in the world of fintech. Perhaps companies will only become “back-end” infrastructure providing shopping inventory or operations like customer support or deliveries. Or perhaps we’ll come back to Google Adwords 2.0.
But we do know that LLMs aren’t sticking to be just horizontal players building ecosystems.
Why the Travel Vertical Matters
Back to where we started: OpenAI’s agent can now book travel using a web-browser and Expedia. Perplexity has a formal travel vertical. Though delayed, Google (Gemini) Trip Planner is leveraging flights, maps, and gmail data to automate trips. Anthropic’s agent “mimics a travel agent.” LLMs have been using travel ad nauseam, to the point of sparking public complaints.
Why are LLMs obsessed with showing off travel? Perhaps it’s because travel is associated with positive emotions. Or perhaps it’s geared towards a tech/ finance audience who tends to travel frequently.
The simpler answer is that it’s data driven. Travel is an attractive market. Colin Jarvis at OpenAI noted travel is one of the most common topics users search for on ChatGPT, which is probably why so many demos are based on travel. McKinsey also estimates that consumer travel market is $8.6 trillion, equivalent to roughly 9% of global GDP. Building on this is my view:
Gen-AI Is Freeing Up 300 Billion Hours. And Travel Will Spend It.
My exploratory hypothesis is that the travel market will grow at a rate highly correlate to actual free time and money generated by AI with at least four tailwinds:
Surplus Creation → McKinsey suggests that GenAI has “the potential to automate work activities that absorb 60 to 70 percent of employees’ time.” Giving people an “extra” Friday. My former employer, Oliver Wyman, echoes that statement saying there may be 300B free hours globally.
Travel Eats Up 50% of Surplus → In the largest 4-day-week pilot in UK, studies found that over HALF of participants spent the extra day on leisure and travel. Even anecdotally, travel volume increases during holidays globally.
Cultural Momentum & Infrastructure → Travel is TikTok’s fastest-growing vertical (+410 % since ’21) and a top Instagram niche. At the same time, countries are building infrastructure with over 40 countries now provide digital nomad visas (according to Deel, a $12bn HR startup) and 80% of studied companies offer some level of remote work for domestic and international travel according to Deloitte.
Friction Reduction → $40B in travel-tech VC since ’21 in startups to make travel easier, while incumbents are deploying LLM tools, and horizontal players are creating travel verticals. There are dozens of unicorns and promising early startups all with the aim to make traveling delightful.

So it makes sense that LLMs are taking on travel, especially with new agent capabilities, which can make travel frictionless. There are opportunities and threats for the sector as we can expect from any major platform shifts.
Companies in the space aren’t passive victims sitting around doing nothing. In fact, startups and incumbents seem to be moving faster than ever on the forefronts of search, consumer, and infrastructure.
Similar to how companies are using LLM-wrappers with foundational model assets, LLMs are also leveraging infrastructure of incumbents — or at least for now. While LLMs demonstrate significantly more power today, they still need the infrastructure, operations, brand equity, and assets of these players.
There is a window of opportunity to ride this wave.
Fascinating analysis, Dan
Interesting takes Dan!
“Once the “hallucination problem” becomes relatively solved, the reliance on external sources for credibility will diminish.”
— I think this is where the devil lies. Hallucinations aren’t just a bug of LLMs. They’re a fundamental part of this architecture and model paradigm. LLMs at the end of the day are trying to maximize the likelihood of what they output, so they will always have cases where they say something incorrect, esp when reality doesn’t match up with what is expected.
Chain of thought models do try to solve this by adding enough context as to change what is considered a “likely” continuation by the model, but hallucinations are by and large here to play